TokenLearner: What Can 8 Learned Tokens Do for Images and Videos?

2021년 10월 5일 arXiv에 submission version으로 TokenLearner를 Review하고자 합니다. (NeurIPS 2021)
Abstract
최근 이미지와 비디오 인식에서 attention 적용은 hand-designed tokens 방법(e.g. ViT의 경우 16 x 16 Patch로 크기를 고정하여 제한된 수의 token을 사용)으로 처리할 경우 의미가 있는 token만을 나타내기 어려운 부분이 있습니다. 따라서 이를 Adaptive하게 적용할 있는 의미 있는 token들을 나타낼 수 있다면 긴 비디오의 시간축과 고해상도의 이미지에서 의미가 있는 token들 만을 학습하여 효과적으로 나타낼 수 있게 됩니다. 따라서 Dimension이 큰 입력값에서의 token들을 adaptive하게 학습함으로써 연산량을 줄이고 의미있는 token들만을 배울 수 있게 되는 것입니다. 이를 검증하기 위해 ImageNet에 적용하여 연산량을 줄였고 Kinetics-400, Kinetics-600, Charades, AViD benchmarks에서 SOTA를 달성하였습니다.
1.Introduction
이미지와 비디오는 많은 양의 시각적인 정보를 제공하고 있습니다. 이를 해석하기 위해 오랜기간 다양한 연구들이 진행되어 왔고 비디오의 경우 RGB의 Frame정보뿐만아니라 시간축의 정보까지 함께 해석해야합니다. 따라서 정보량은 많아지게되고 이를 효율적으로 빠르게 처리할 수 있는 방법을 고민해 온 것입니다. 최근 CNN구조에서 Transformer만을 적용한 ViT가 나오면서 이미지를 patch단위로 구성하여 자연어 처리(e.g. BERT, GPT-3)와 같이 좋은 성능을 나오는 방법들이 나오고 있는 상황입니다. Image(2D-patch)나 Video(3D-cubelet) token들을 적용하는 과정에서 긴 시간축을 가진 비디오의 경우에는 token의 수가 많아지기에 연산량이 많아지는 문제점이 있습니다. 따라서 이를 어떻게 효과적으로 해결할지에 대해 고민을 하였고 입력값의 토큰에 대한 중요한 부분을 학습을 통해 tokenize화 할 수 있다는 것을 알게 되었습니다. 또한 적은 수의 토큰만으로도 효과적으로 처리할 수 있고 연산량도 감소시킬 수 있다는 것을 확인하였습니다. 이를 Transformer모델에 적용하였고 기존 모델 대비 좋은 성능을 확보할 수 있었습니다.
2 TokenLearner Modules for Adaptive Tokenization
ViT의 경우 작은 Patch단위(e.g. 16 x 16)나뉘어져 있고 비디오 영역의 ViViT나 TimeSFormer의 경우에도 2D나 3D의 시공간에서의 고정된 cube형태의 token들로 나뉘어져 있습니다. 이처럼 token들을 고정하기 보다 attention modules를 적용하여 token을 배울 수 있게 한다면 더 중요한 특징을 얻을 수 있습니다.
1) 입력값에 대해 동적으로 token들을 선택함으로써 token을 adaptive하게 처리할 수 있습니다.
2) 비디오의 경우 많은 수의 토큰으로 구성되어 있습니다. (e.g. 4096) 따라서 토큰 수에 따라 quadratic한 연산량이 필요로 하고 토큰 수를 줄임으로써 연산량을 효과적으로 줄일 수 있습니다.
3) 또한 비디오상에서 시간축에 따라 다른 공간상의 정보를 토큰화를 통해 다른 layer에 전달함으로써 ViT나 ViViT와 같은 Transformer아키텍쳐와 함께 활용할 수 있습니다.
2.1 TokenLearner
Input X는 $X \in \mathbb{R}^{T \times H \times W \times C}$(T는 시간축, H x W는 공간, C는 채널)에서 $X_{t}$의 경우 특정 시간에서의 image라고 볼 수 있습니다. $t: X_{t} \in \mathbb{R}^{H \times W \times C}$ 여기서 각 시간축인 t에 따른 프레임 $X_{t}$를 S개의 tokens로 나눌 수 있고 이를 $Z_{t}=\left[z_{i}\right]_{i=1}^{S}$로 정의할 수 있습니다.
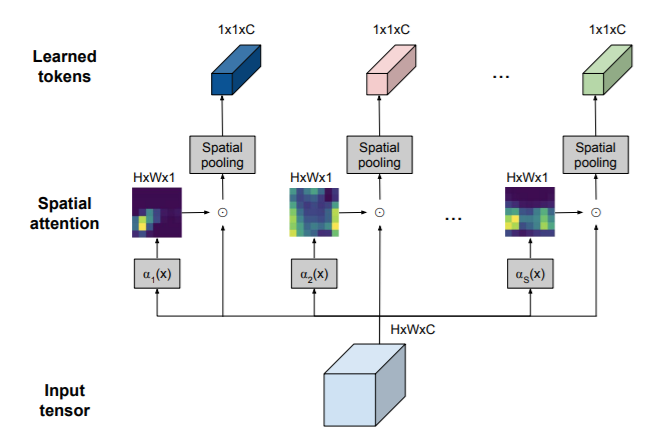
위 그림은 Single Image에 TokenLearner 모듈이 적용된 내용으로 TokenLearner는 Input Image인 pixel들의 집합을 Spatial Attention을 통해 각 token을 adaptive하게 생성해내게 됩니다. 이를 $z_{i}=A_{i}\left(X_{t}\right)$로 정의하고 spatial attention을 적용한 각각의 토큰 $z_{i}$를 생성하는 tokenizer입니다. 이를 수식으로 나타내면 아래와 같이 정의할 수 있습니다.
\[⁍\]입력값인 Single Image $X_{t}$에 Spatial Attention을 적용 후 Broadcasting function $\gamma(\cdot)$로 matrix를 구성한 후 입력 값 $X_{t}$와 Hadamard product($\odot$)로 각 element간의 곱을 연산한 후에 각 채널 별 spatial영역에 global average pooling을 통해 1 x 1 x C (i.e. ${R}^{C}$) 토큰을 생성하게 됩니다. 각 토큰은 다음과 같은 영역으로 구성되게됩니다. $Z_{t}=\left[z_{i}\right]_{i=1}^{S}\in \mathbb{R}^{S \times C}$
Spatial self-attention이 적용되는 ${\alpha_{i}\left(\cdot\right)}{i=1}^{S}$의 경우 spatial의 attention을 구하기 위해 1개나 여러개의 CNN으로 sigmoid 함수와 함께 구현되었고 다른 방법들로도 확장할 수도 있습니다. 비디오에서의 이미지를 $Z=Z{t}$로 각 토큰을 $Z\in \mathbb{R}^{ST \times C}$로 나타나게 됩니다.
TokenLearner 구현의 핵심인 Spatial Attention을 정리한 블로그와 코드입니다.
import torch
import torch.nn as nn
class BasicConv(nn.Module):
def __init__(self, in_planes, out_planes, kernel_size, stride=1, padding=0, dilation=1, groups=1, relu=True, bn=True, bias=False):
super(BasicConv, self).__init__()
self.out_channels = out_planes
self.conv = nn.Conv2d(in_planes, out_planes, kernel_size=kernel_size, stride=stride, padding=padding, dilation=dilation, groups=groups, bias=bias)
self.bn = nn.BatchNorm2d(out_planes,eps=1e-5, momentum=0.01, affine=True) if bn else None
self.relu = nn.ReLU() if relu else None
def forward(self, x):
x = self.conv(x)
if self.bn is not None:
x = self.bn(x)
if self.relu is not None:
x = self.relu(x)
return x
class ChannelPool(nn.Module):
def forward(self, x):
return torch.cat( (torch.max(x,1)[0].unsqueeze(1), torch.mean(x,1).unsqueeze(1)), dim=1 )
class SpatialGate(nn.Module):
def __init__(self):
super(SpatialGate, self).__init__()
kernel_size = 7
self.compress = ChannelPool()
self.spatial = BasicConv(2, 1, kernel_size, stride=1, padding=(kernel_size-1) // 2, relu=False)
def forward(self, x):
x_compress = self.compress(x)
x_out = self.spatial(x_compress)
scale = F.sigmoid(x_out) # broadcasting
return x * scale
Compute reduction in Transformers:
TokenLearner로 학습된 토큰 Z는 ViT나 ViViT에서 사용되는 multi-head selfattention (MHSA)의 입력 값으로 사용될 수 있습니다. 이 경우 후속 Layer는 의미 있는 토큰으로 구성된 적은 수의 토큰만으로 학습이 가능하게 되는 것입니다.(e.g. 1024개가 아닌 8개의 토큰) 따라서 토큰 수에 따른 quadratic한 연산량을 대폭 감소시킬 수 있고 네트워크상의 어떠한 위치에도 추가될 수 있습니다. 또한 TokenLearner가 적용된 이후의 Transformer의 경우 토큰의 수가 크게 감소했기 때문에 연산량이 무시할 수준이 되는 것입니다.
2.2 TokenFuser
TokenLearner가 토큰의 수를 줄이는 반면 TokenFuser는 토큰의 정보를 융합하고 기존 spatial정보를 의미있게 재구성하는 역할을 가지고 있습니다. 따라서 필요에 따라 토큰의 정보를 구성해 입력값을 복원할 수 있습니다.
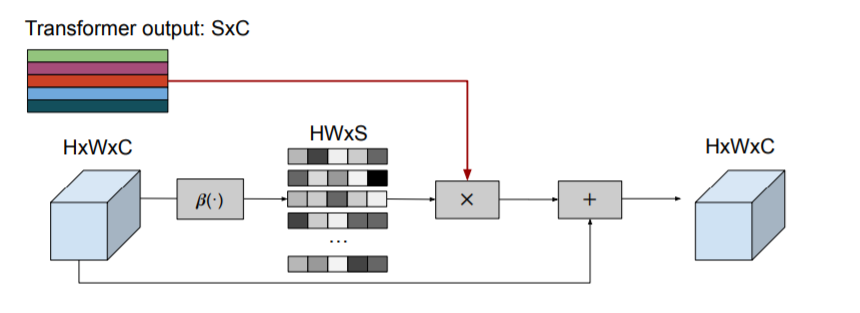
Transformer layer의 out 값인 $Y\in \mathbb{R}^{ST \times C}$에서 각 채널에 독립적으로 토큰별로 MLP layer과 같은 linear layer을 적용하여 ${R}^{ST \times C}\rightarrow{R}^{ST \times C}$로 정의되며 out값 $Y=(Y^{T}M)^{T}$로 M은 ST x ST matrix크기를 가지는 Learning Matrix라할 수 있습니다. 따라서 결과적으로 token-wise간 linear layer을 통해 token간의 패턴을 학습하여 ST x C의 크기를 가지는 tensor가 생성되는 것입니다. TokenFuser의 식을 아래와 같이 정의되고 $X_{t}^{j}$는 앞쪽 Tokenlearner로 부터 생성된 output이고 $Y_{t}$는 TokenFuser로 생성된 token입니다. $\beta_{i}\left(X_{t}\right)$는 단순한 linear layer와 sigmoid function을 통해 나온 weight tensor입니다.
\[X_{t}^{j+1}=B\left(Y_{t}, X_{t}^{j}\right)=B_{w} Y_{t}+X_{t}^{j}=\beta_{i}\left(X_{t}^{j}\right) Y_{t}+X_{t}^{j}\]3 Experiments with Images
TokenLearner을 검증하기 위해 image representation learning에 시도하였고 1) Transformer 모델에 단순히 삽입하거나 2) Transformer 모델에 복수 위치로 삽입 후 TokenFuser를 사용하는 2가지 아키텍쳐로 평가하였습니다.
3.1 Network architecture implementation
Tokenlearner ViT 기반 아키텍쳐로 ViT-B/16과 ViT-L/16을 backbone로 사용하였고 ViT-B/32도 상용하였는데 /32의 경우 patch size를 32 x 32로 셋팅한 아키텍쳐입니다.(e.g. /16은 16 x 16, /32는 32. x 32) ViT-S의 경우 채널 수를 384개로 하였고 ViT-S와 ViT-B의 경우 Transformer Layer 수를 12로 하였고 ViT-L이 경우 24개로 한 구조입니다. input resolution에 따라 각 토큰의 크기가 16 x 16이기에 각 토큰의 수는 224 x 224 (196개-14 x 14), 384 x 384(576개-24 x 24), 512 x 512(1024개-32 x 32)로 dataset과 model에 따라 달라질 수 있습니다.
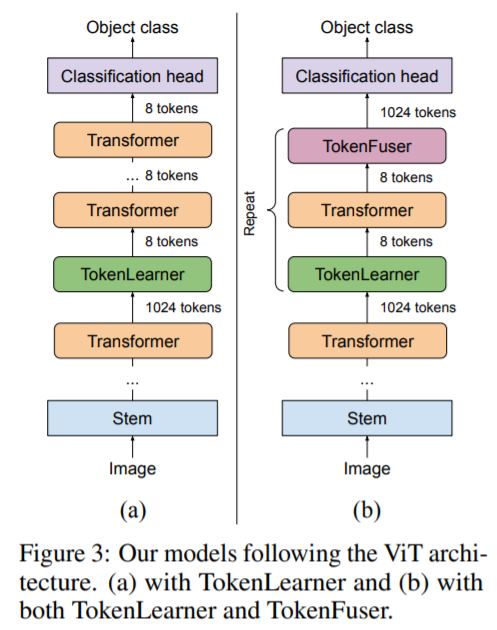
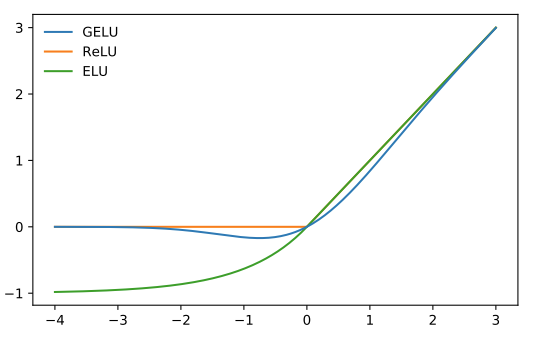
위 그림은 ViT-B 구조에서 12개의 layer중에 6번째 Layer에 삽입한 구조입니다. a)의 경우 Tokenlearner만을 삽입한 반면 b)의 경우에는 TokenLearner-Transformer-TokenFuser로 구성한 구조입니다. 또한 6 Layer 이후 7~12Layer까지 위 구조를 반복하여 반영한 구조라고 할 수 있습니다. Layer수는 21개등으로 수정할 수 있습니다. 다만 Layer 수가 증가함에 따라 연산량이 증가할 수 있기에 Tokenlerner를 통해 토큰의 수를 8개나 16개로 줄일 수 있습니다. 본 논문에서는 S = 8, 16, 32개로 실험해보았고 기본값으로 8과 16으로 셋팅하였습니다. Spatial Attention의 경우 4개의 3x3 conv layer과 gelu(Activation Function)[1]로 채널별로 독립적으로 구현되었습니다. 학습셋팅과 관련하여서는 ViT의 파라미터와 같게 셋팅하였습니다.(e.g. learning rate, epoch등)
[1] Hendrycks, Dan and Kevin Gimpel. “Gaussian Error Linear Units (GELUs).” arXiv, 2016.
3.2 Image classification datasets
ImageNet: image benchmark에서 가장 많이 쓰이는 ImageNet(1000카테고리, 1.1M장의 이미지)로 Resolution이 384 x 384의 경우 ViT의 S/16과 B/16을 사용하였고 512x512의 경우 ViT의 L/16모델을 사용하였습니다. 또한 모델의 일반화를 평가하기 위해 ImageNet ReaL로 평가를 진행하였습니다.
JFT-300M. 구글 내부적으로 수집한 JFT-300M은 Transformer 아키텍쳐로 구성된 큰 모델을 학습시키기 위해 만8천개의 클래스와 3억장의 이미지로 구성된 데이터입니다. 본 실험에서는 ViT에서와 같이 Pre-training용도로 사용하였고 image resolution은 224 x 224로 정하였습니다.
3.3 Ablation: where should we have TokenLearner?
가장 먼저 모델에서 TokenLearner의 위치가 어디에 위치하는 것이 성능이 좋은 것인지를 실험하였습니다. JFT-300M으로 Pre-Training한 모델을 few-shot learning으로 적용하였고 TokenLeaner의 위치에 따른 연산량도 함께 확인하였습니다. TokenLearner적용에 따라 Token의 수는 기존 196개에서 8개로 감소하였고 그에 따라 연산량도 감소한 것을 확인할 수 있었습니다. (TokenFuser는 미적용)
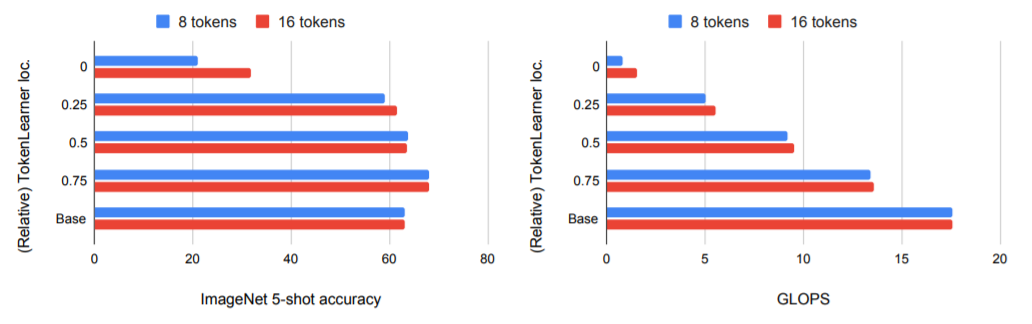
Y축의 TokenLearner의 적용 위치에 대한 값으로 0은 가장 앞 Layer에 적용, 0.5는 중간 Base의 경우 적용을 안한 성능을 나타냅니다. 실험결과 TokenLearner을 중간에 넣었을때 연산량은 감소하면서도 기본 성능과 유사한 정확도를 보여주었고 0.75(네트워크 후반부인 3/4의 위치)의 경우 정확도는 기본성능도 올라가고 연산량도 감소하였습니다. (가장 앞에 TokenLearner을 적용시에 의미 있는 정보가 많이 사라져서 정확도가 오히려 떨어진 것으로 판단됩니다.)
3.4 Results
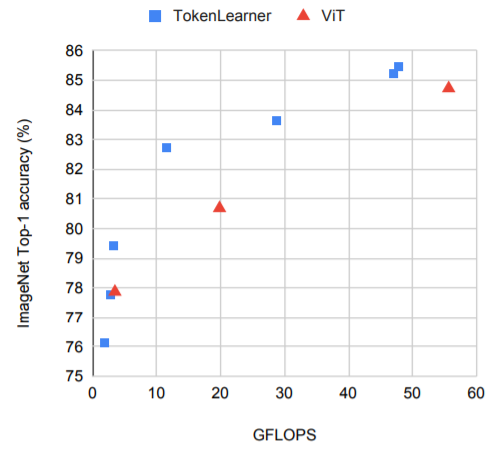
위 그림은 ImageNet fine-tuning에 대한 ViT와 Tokenlearner을 시각화한 그림입니다. X축은 GFLOPs에 대한 연산량을 나타낸 지표로 Y축 ImageNet Top-1 정확도화 비교한 그림입니다. TokenLearner 적용을 통해 정확도도 올라가고 연산량도 감소되는 것을 확인할 수 있습니다.

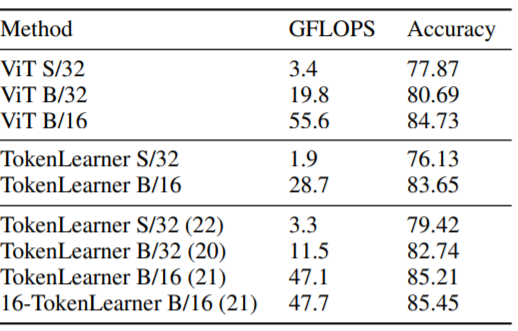
ImageNet fine-tuning Top1 정확도와 GFLOPS를 나타낸 표로 괄호의 숫자는 Transformer Layer의 수를 나타내고 /16과 /32는 Patch 크기를 나타앱니다.)
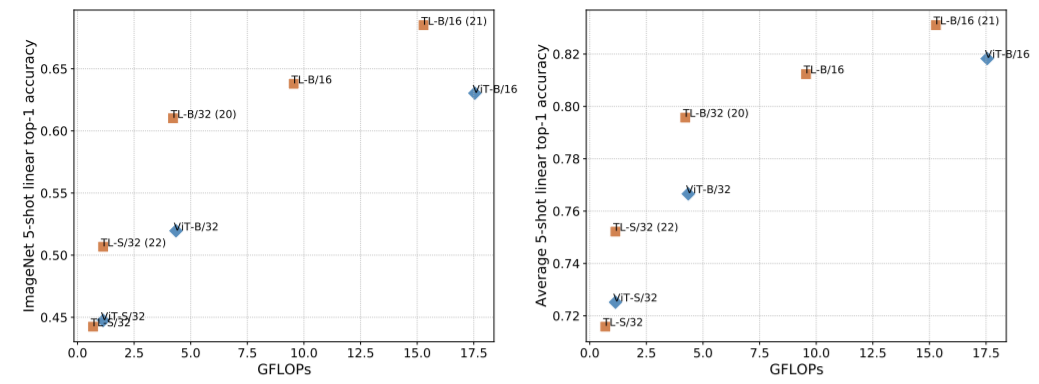
Few-shot(5-shot) Classification에 대한 TokenLearner(TL) 적용에 따른 결과입니다. 왼쪽은 이미지넷에 대한 결과이고 오른쪽은 여러 데이터셋(Caltech101, Caltech-UCSD Birds 2011, Cars196, CIFAR100, olorectal_histology, DTD, ImageNet, Oxford-IIIT Pet, and UC Merced Land Use Dataset)의 평균 정확도를 나타낸 그림입니다.
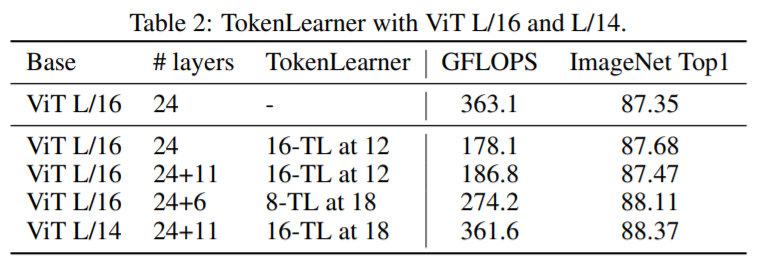
위 테이블은 ViT L과 같이 큰 모델에서 TokenLearner을 적용했을때의 성능을 비교한 표입니다. Layers 컬럼의 +11의 경우 기본 Layer에 11개의 Layer를 추가로 적용한 내용으로 TokenLearner가 적용되었기 때문에 Layer 수가 추가되더라도 Token의 수가 줄어들어 FLOPS의 증가량은 적은 것을 확인할 수 있습니다. 또한 “16-TL at 12”의 경우 16개의 Token이 12번째 Layer에 적용되었다는 의미입니다. 뒤쪽 Layer에 적용될 수록 TokenLearner의 적용이 늦어지는 만큼 토큰의 수가 앞쪽 Layer에서 많기에 연산량은 더 증가하기 마련입니다.
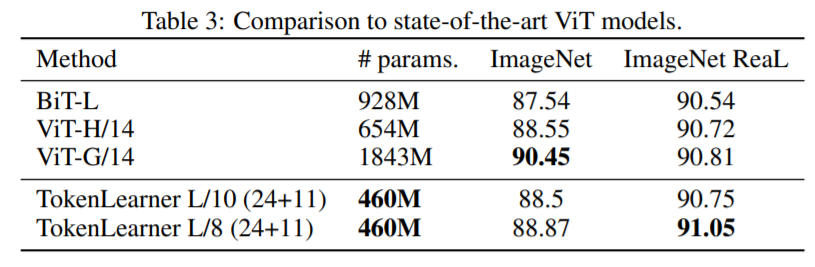
위 테이블은 ViT의 Large Model과 비교하여 TokenLearner적용으로 파라미터 수는 줄은 반면 더 나은 성능을 보여주는 것을 볼 수 있습니다. 또한 입력 Patch Size에 따라 파라미터 수는 유지하면서 정확도를 올린 것도 확인할 수 있습니다.
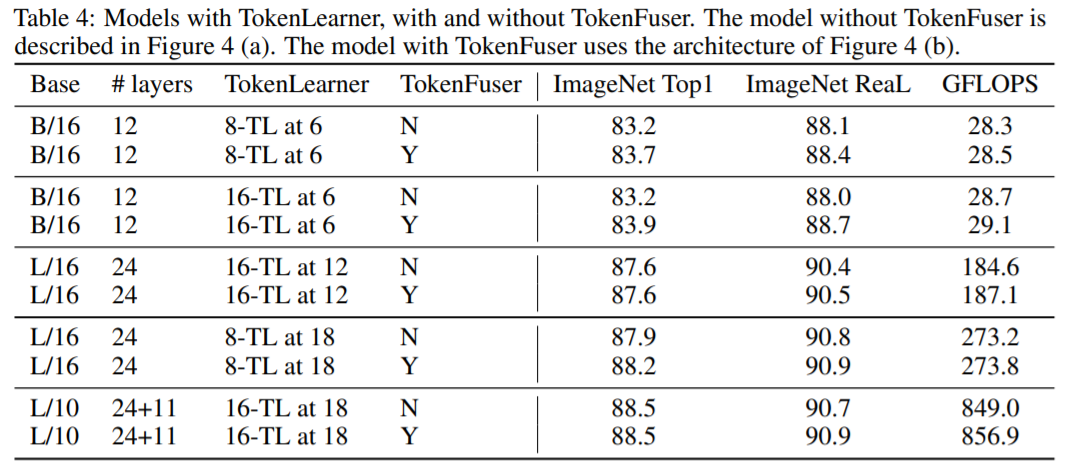
위 테이블은 TokenFuser 적용에 따른 결과를 정리한 표입니다. TokenFuser 적용에 따라 성능이 소폭 상승한 것을 확인할 수 있습니다.
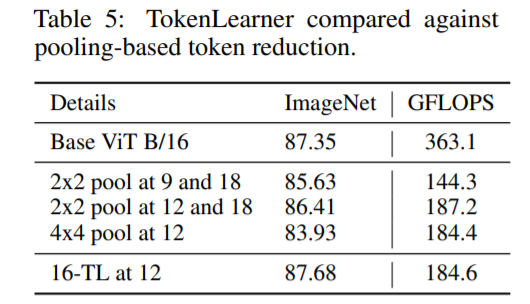
TokenLearner 모듈에 토큰수를 감소하기 위한 Spatial Pooling를 적용한 결과입니다. Pooling연산에 따라 정확도는 감소한 반면 연산량의 차이는 없었습니다.
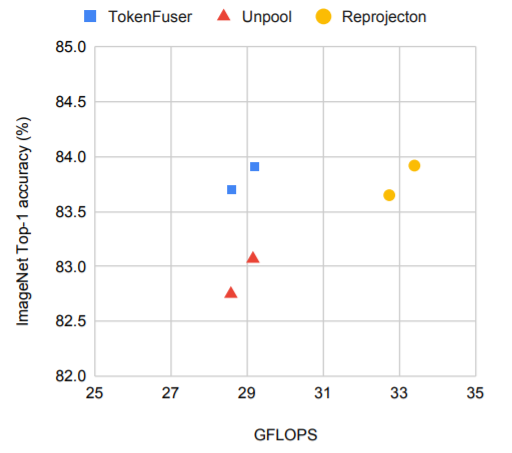
TokenFuser을 적용시 Unpooling(TokenLearner에 mask를 적용하여 입력 tensor값 복원)과 Reprojection(Transformer Layer을 통한 원레 Token 수 복원)을 비교한 그림입니다. TokenFuser 적용이 연산량이나 정확도 측면에서 더 나은 성능을 보여주고 있습니다.
4 TokenLearner for Videos
비디오 인식에서 TokenLearner의 역할을 살펴보면 비디오의 경우 시간축 t가 있기에 TokenLearner이 적용된 $Z$를 시간축에 따라 $Z_{t}$를 생성하게 됩니다. 아래 그림은 비디오 영역에서의 TokenLearner가 적용된 아키텍쳐로 TokenLearner이 각 프레임 별로 S개의 토큰을 생성합니다. 따라서 시간축의 정보인 T를 포함하여 ST의 토큰의 수 만큼 생성하게 됩니다. 생성된 토큰을 Transformer layer에서 시간축과 공간축에 대한 패턴을 학습하게 되고 TokenFuser을 통해 경량화된 Tensor로 복원할 수 있습니다. Figure 3 (b)에서와 같이 TokenLearner, Transformer, TokenFuser 모듈을 반복적으로 적용할 수 있습니다. Figure 3 (a)는 TokenLearner 모듈이 적용되어 토큰이 생성 후 Transformer layers의 반복적용이 가능하게 됩니다.
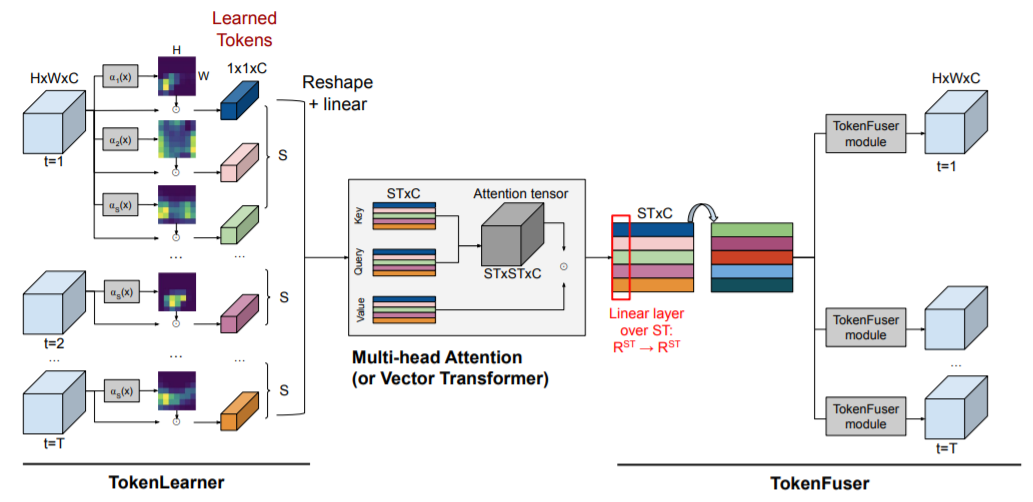
정리하면 TokenLearner(토큰생성), Transformer(relation계산), and TokenFuser(재결합)를 합친 아키텍쳐로 모듈 형태로 적용이 가능합니다.
5 Experiments with Videos: TokenLearner with Video Vision Transformer
ViViT 모델을 바탕으로 Tokenlearner를 적용한 결과입니다. ViViT 모델은 JFT로 Pre-training를 진행한 Weight를 Kinetics data를 바탕으로 Fine-tuning을 진행하였고 비디오 인식을 위한 3D 구조인 만큼 patch의 크기를 16x16x2로 셋팅하였습니다.
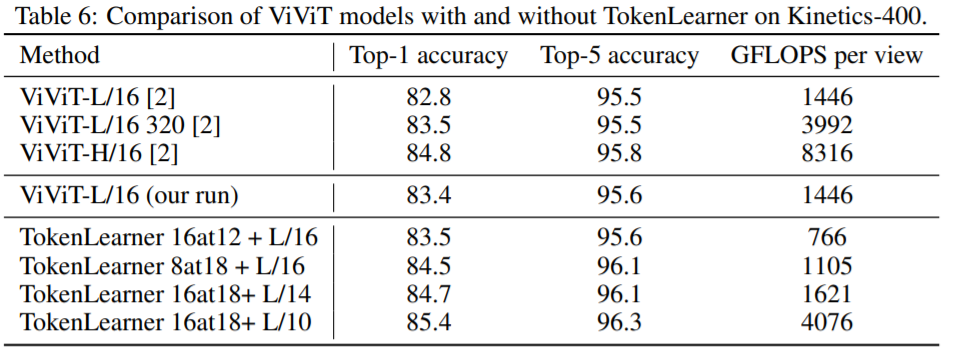
Table 6는 Kinetics-400 data를 바탕으로 ViViT모델에 TokenLearner 적용에 따른 결과를 보여주는 내용입니다. “TokenLearner 16at12”의 경우 16개의 토큰을 생성하고 12번째 Transformer Layer 이후에 적용한 것을 나타내는 것입니다. TokenLearner 적용에 따라 연산량은 줄어들면서도 정확도는 올라가는 것을 확인할 수 있습니다.
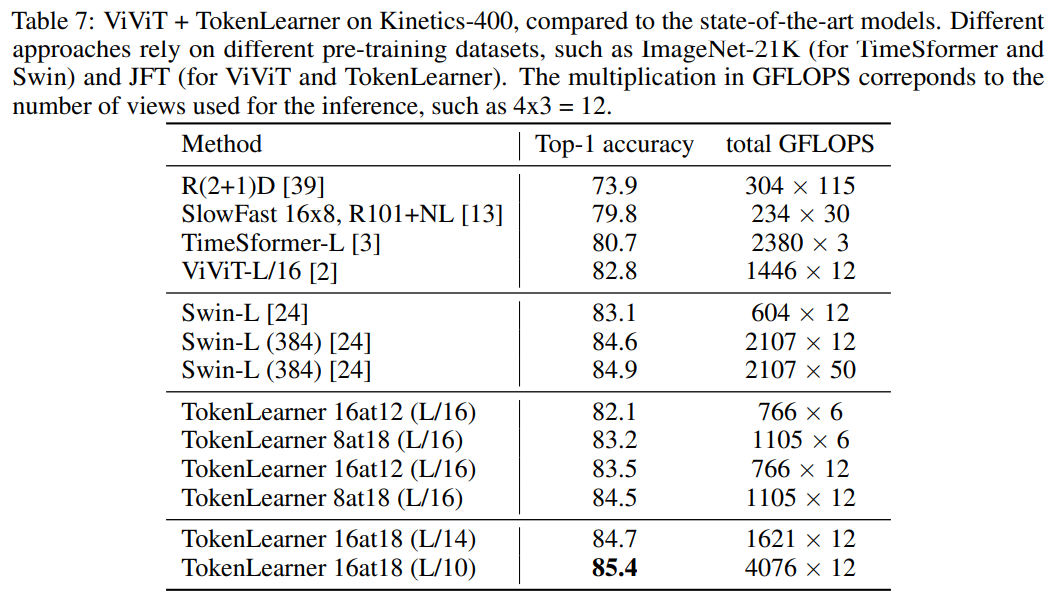
Table 7의 경우 현재 최고의 성능을 보여주는 모델(Swin Transformer)과 비교하여 TokenLearner을 적용했을 때의 성능을 비교한 내용입니다.
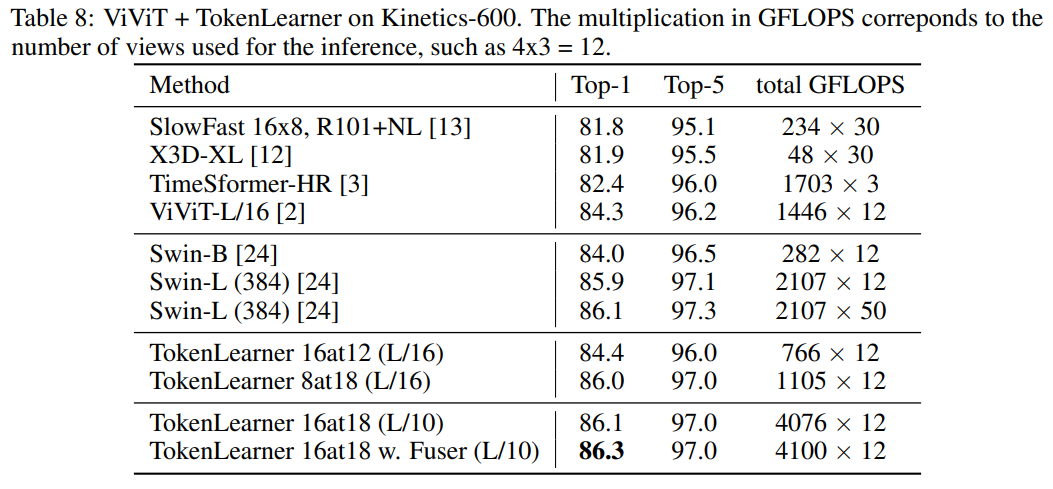
Table 8의 경우 Kinetiec-600 dataset으로 비교한 내용으로 TokenLearner 적용에 따라 더 좋은 성능을 보여주는 것을 확인할 수 있습니다. (L/10의 경우 ViT-L모델의 10x10 Patch)
6 Experiments with Videos: TokenLearner with Bottleneck Transformer
6.1 Network architecture implementation
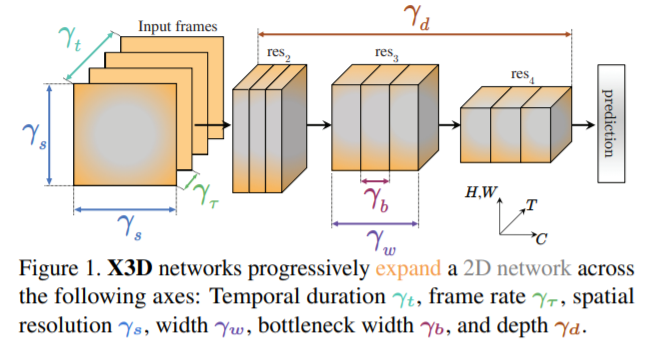
Video 분류를 위한 실험으로 X3D backbone에 Bottlenetck Transformer구조로 TokenLearner를 적용을 하였습니다. X3D는 시간축의 정보와 width, height, depth등을 종합적으로 고려하여 연산량과 정확도를 고려하여 설계한 최적의 네트워크로 computation과 accuracy의 trade-off를 네트워크 구조를 설계하여 해결하였습니다.
[2] Christoph Feichtenhofer. “X3D: Expanding Architectures for Efficient Video Recognition.” CVPR(oral), 2020.
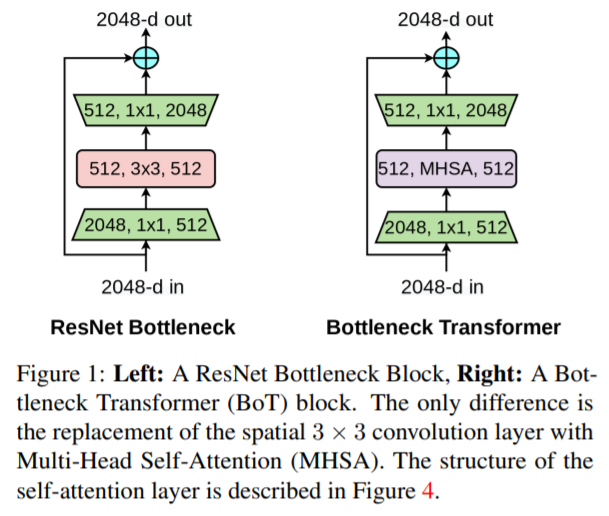
Bottlenetck Transformer구조는 ResNet의 Bottlenet block의 3 x 3 CNN 구조를 Transformer의 Multi head self attention으로 변경한 구조입니다.
[3] Aravind Srinivas, et al, “Bottleneck Transformers for Visual Recognition.” arXiv, 2021.
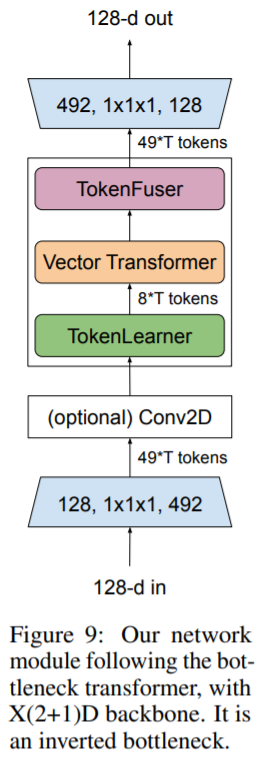
위 구조를 조합하여으로 아래의 아키텍쳐를 구성하였고 TokenLearner 적용을 위해 2D(3 x 3) CNN Layer에 1D Temporal CNN Layer를 조합하여 X(2+1)D 모듈을 구성하였습니다. TokenLearner의 spatial attention function은 1개의 2D CNN을 적용하였습니다. Transformer구조는 전체적인 시간축의 정보와 채널간의 관계를 더 잘 나타내기 위해 MHSA(Multi Head Self Attention)대신 Vector Transformer을 적용하였고 video training을 위해 224 x 224 x 64로 test를 위해 256 x 256 x 64로 구성하였습니다. TokenLearner의 input은 8 x 8 x 64로 output channel은 64로 정하였고 long-term video에 대한 최적의 셋팅 값을 64frmaes에 토큰의 수를 8개로 정하였습니다.
통해 2가지 Dataset에서 실험을 진행하였습니다.
6.1.1 Datasets
Charades dataset
평균 30초나 되는 긴 시간축의 정보를 담은 데이터로 8000개의 training과 1686개의 validation set으로 구성되어 있습니다. activity classes수는 157개로 동시에 여러 action들이 발생하는 상당히 어려운 dataset입니다. 실험을 위해 mAP(mean Average Precision)로 평가하고 6fps와 12fps로 frame rate를 셋팅하였습니다.
[4] G. A. Sigurdsson et al. “Hollywood in homes: Crowdsourcing data collection for activity understanding.”, ECCV, 2016.
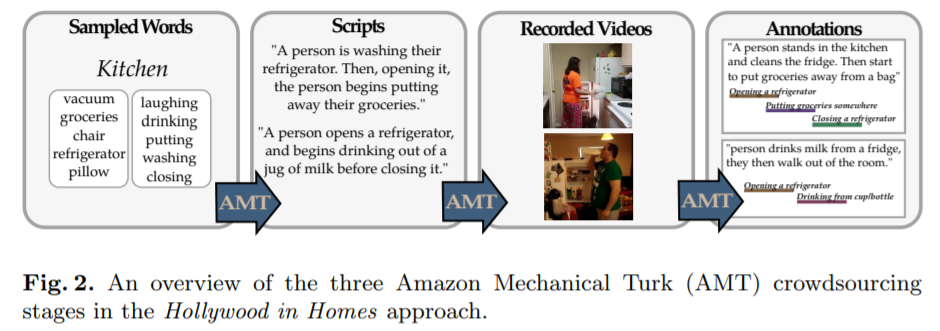

AViD dataset
Anonymized Videos from Diverse countries (AViD) dataset은 Kinetics의 concept을 반영하여 다양한 나라에서 여러 종류의 Video clip을 모은 데이터로 887개의 class와 45만개의 video set(41만개 train, 4만개 test)로 구성되어 있습니다. 각 video는 3초에서 15초 정도로 연구용으로 제공된 데이터 셋입니다.
[5] AJ Piergiovanni and Michael S. Ryoo “AViD Dataset: Anonymized Videos from Diverse Countries” in NeurIPS 2020.
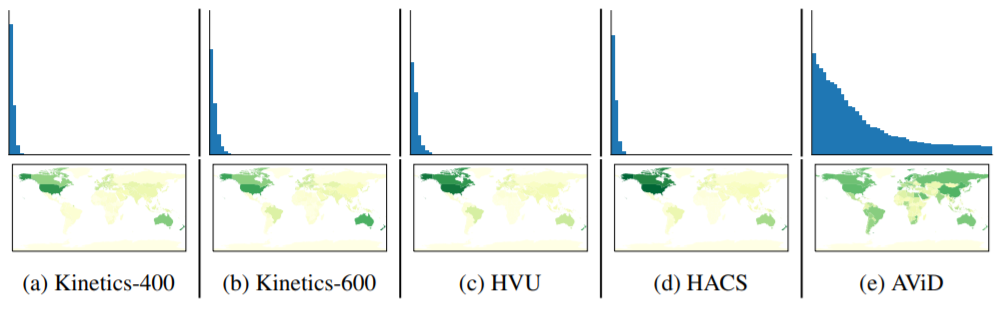
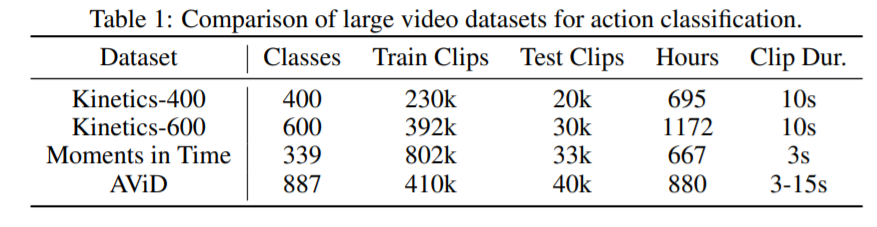
Video Classification에서 가장 많이 사용되는 Kinetics-400, Kinetics-600과 비교한 데이터의 분포입니다.
6.2 Results
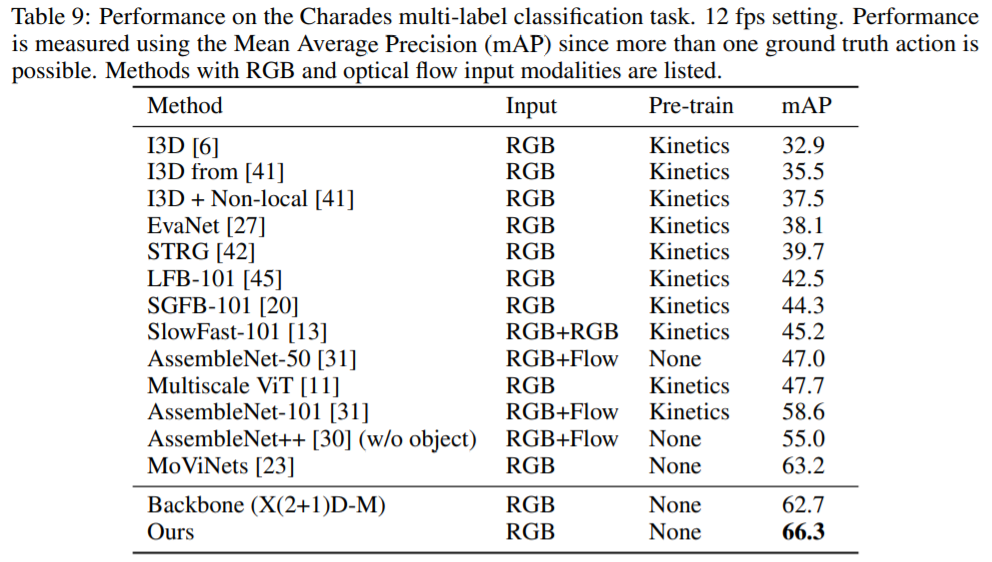
Charades dataset에서 아래 Table과 같이 mAP가 66.3%의 SOTA를 달성하였습니다.
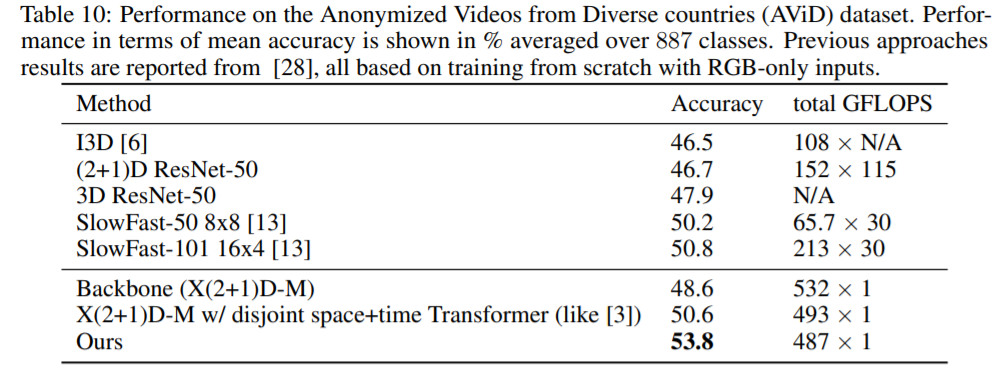
AViD data의 경우에도 RGB만을 사용하여 아래 테이블과 같이 연산량을 줄이면서도 정확도는 가장 높은 수치를 달성하였습니다.
6.3 Ablations
Comparison against different tokenizations:
TokenLearner적용에 대한 space-time별 토큰화를 위해 TokenLearner + Vector Transformer + TokenFuser 모듈에 따라 적용한 결과입니다.
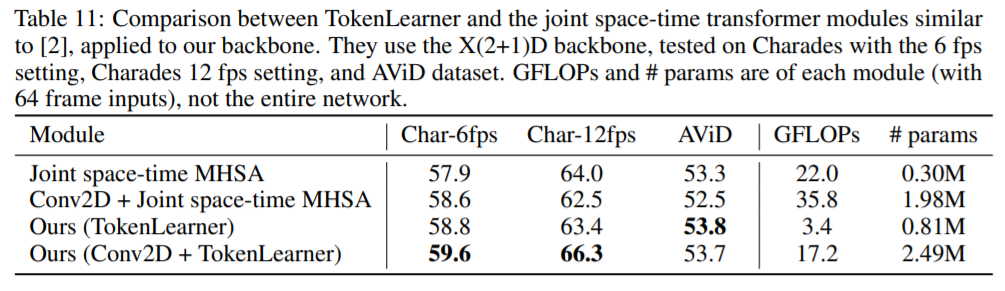
Comparison between multiple space-time layer combinations.
TokenLearner적용에 따른 Charades dataset에 대한 결과입니다. 64-frmes setting에 따라 토큰 수는 transformer의 경우 8 x 8 x 64 = 4096인반면 TokenLearner의 적용에 따라 8 x 64 = 512개의 토큰만으로 연산할 수 있습니다.
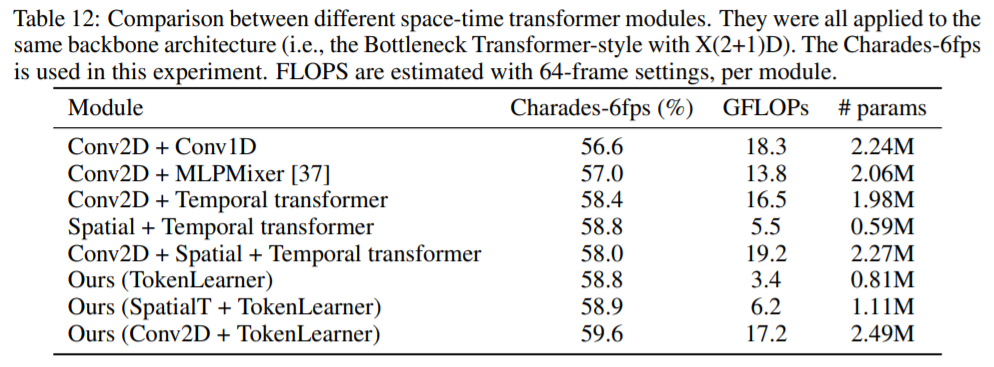
More TokenLearner alternatives.
Spatial Attention을 적용한 TokenLearner에 대한 다른 실험으로 Charades dataset에 대해 1) 각 프레임 별로 토큰의 수를 8개로 고정하여 적용하는 방법의 경우 58.8%의 정확도를 달성하였고 2) fully connected layer를 통해 토큰을 생성하는 방법(e.g. spatial attention의 방법을 dense layer로 적용)의 경우 56.6%의 정확도를 3) 전체 프레임에 대해 average pooling를 적용하여 프레임별로 여러개의 토큰을 생성하는 방법을 적용하는 경우 58.6%의 정확도로 Spatial Attention을 적용한 경우 성능이 가장 좋은 것을 확인할 수 있었습니다.(59.6%)
6.4 Visualizations
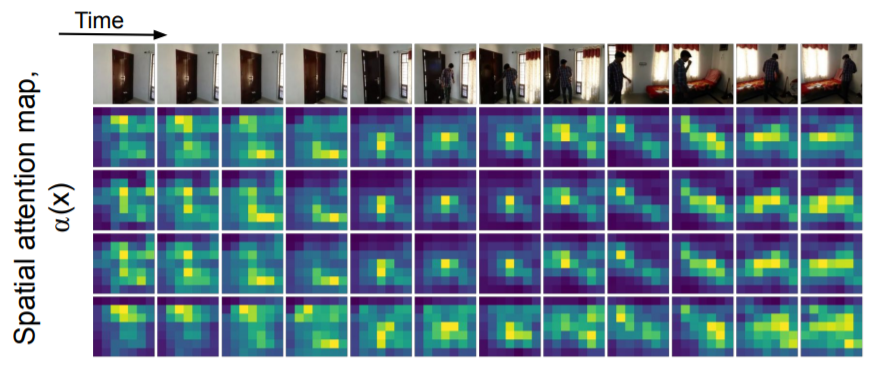
위 그림은 8개의 토큰 중 4개의 토큰을 시간축에 따른 Spatil Attention Map(i.e. $\alpha_{i}(x)$)를 나타낸 그림입니다. 위 그림을 통해 시간 축에 따라 human에 focus하는 것을 확인 할 수 있습니다.
7 Related work
Video understantiong의 경우 시공간상의 정보를 해석해야 하기에 모션과 뷰 정보를 알맞게 뽑아내야합니다. 3D정보 추출을 위해 (2+1)D CNN이 사용되어 왔고 two-stream(RGB+Optical Flow) 아키텍쳐들도 활용되어 왔습니다. 최근 Attention 기반의 Transformer아키텍쳐가 image분류와 비디오 인식에서 큰 성능 향상을 이뤄오면서 토큰 수에 따른 연산량을 줄이기 위한 부분에서도 연구가 진행되어 왔습니다. Video의 경우 $O(N^3)$ 연산량을 처리해야하기에 의미있는 토큰을 추출하여 N의 수를 줄이는 연구가 필요한 것입니다.
8 Conclusions
Image와 Video의 representation learning을 위해 input값에 따라 유연하게 적용할 수 있는 TokenLearner를 통해 중요한 Tokens만을 추출해 낼 수 있습니다. 이를 통해 정확도의 향상 뿐아니라 연산량을 감소시킬 수 있었습니다. 현재의 한계점은 frames상의 spatial 정보만을 통해 추출(e.g. spatial attention map)하기에 video 분류과 같은 문제에서는 보다 넓은 시간축으로 확장하여 더 큰 공간과 시간축을 통해 토큰을 추출하는 것을 통해 더 나은 성능을 보여줄 수도 있을 것이고 이를 현재 TokenLearner가 가지고 있는 한계점이라 할 수 있습니다.
9 Reference
[1] Hendrycks, Dan and Kevin Gimpel. “Gaussian Error Linear Units (GELUs).” arXiv, 2016.
[2] Christoph Feichtenhofer. “X3D: Expanding Architectures for Efficient Video Recognition.” CVPR(Oral), 2020.
[3] A. Srinivas et al., “Bottleneck Transformers for Visual Recognition,” CVPR, 2021.
[4] G. A. Sigurdsson et al. “Hollywood in homes: Crowdsourcing data collection for activity understanding.”, ECCV, 2016.
[5] AJ Piergiovanni and Michael S. Ryoo “AViD Dataset: Anonymized Videos from Diverse Countries”, NeurIPS, 2020.