How to train your ViT? Data, Augmentation, and Regularization in Vision Transformers

2022년 5월 TMLR(Transactions on Machine Learning Research)에 게재된 “How to train your ViT? Data, Augmentation, and Regularization in Vision Transformers”를 Review하고자 합니다. (TMLR 2022 by Google Research)
- Openreview : https://openreview.net/forum?id=4nPswr1KcP
- Paper : https://openreview.net/pdf?id=4nPswr1KcP
- Code : https://colab.research.google.com/github/google-research/vision_transformer/blob/master/vit_jax_augreg.ipynb
Abstract
Vision Transformer(ViT)[1]는 image classification, object detection, semantic image segmentation등 다양한 vision application에서 Convolution을 능가하는 성능을 보여주고 있습니다. 이는 CNN, RNN이 가지고 있는 inductive bias를 개선한 아키텍쳐로 인해 ViT가 처음 나올 당시에는 inductive bias를 해결하기 위해 JFT-300M와 같은 Large scale data를 사용하였으나 최근 ViT를 활용한 다양한 아키텍쳐들이 나오고 있는 상황입니다. 본 논문에서는 적은 데이터만으로 학습 시 regularization과 data augmentation(“AugReg”)만으로도 성능 개선을 달성할 수 있었고 ImageNet-21k를 활용하여 ViT의 다양한 모델의 성능을 데이터의 크기와 AugReg에 따른 성능의 향상을 보여주었습니다.
1 Introduction
ViT가 좋은 성능을 보여주긴 하지만 overfitting을 피하기 위해 대량의 학습 데이터가 필요하거나 AugReg 적용이 필요합니다. 하지만 지금까지 데이터의 크기와 model regularization, data augmentation에 대한 관계를 설명하진 못했습니다.
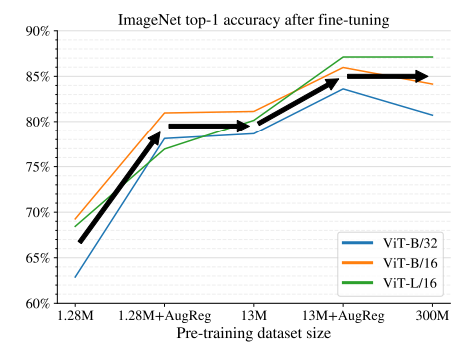
위 그림은 동일한 조건에서 ViT 종류별로 데이터의 크기와 AugReg 적용에 따른 ImageNet의 성능을 나타낸 그림입니다. (ViT-B모델의 경우 JFT-300M보다 ImageNet-21k (13M images)에 AugReg를 적용했을 때 더 나은 성능을 보여주고 있습니다.)
2 Scope of the study
최근 컴퓨터 비전의 딥러닝 모델들은 대량의 데이터셋을 토대로 pre-train 모델을 생성하고 이를 재사용하는 방식으로 만들어 feature extraction용으로 활용을 하면서 다양한 task에 적용하고 있습니다. 본 논문에서는 pre-train모델을 transfer learning에 적용하면서 data에 따라 한정된 자원을 확보한 상황에서 academic과 industry에서 적용 시 효율적인 비용 활용 측면에서의 다양한 관점으로 실험하였고 이를 traing cost와 inference time cost로 분석하였습니다.
3 Experimental setup
실험환경은 TPU에서 JAX/Flax code로 pre-training과 transfer learning을 수행하였고 V100 (16GB)에서 Pytorch image models (timm-SOTA Classification Models)을 통해 Inference 속도를 체크하였습니다.
Dataset은 Pre-Training로는 ILSVRC-2012 (ImageNet-1k-1.3 million training images and 1000 object categories), ImageNet-21k(14 million images with about 21 000 distinct object categories)을 활용하였고 ImageNetV2는 minval accuracy에서 발생하는 overfitting문제를 해결하기 위한 평가 목적으로 활용하였습니다. Transfer learning으로는 VTAB의 4가지 Dataset(CIFAR-100, Oxford IIIT Pets, (or Pets37 for short), Resisc45, Kitti-distance)을 사용하였습니다. main metric으로는 top-1 classification accuracy로 측정하였습니다.
Model의 경우 ViT-Ti, ViT-S, ViT-B, ViT-L의 4개의 설정과 Hybrid Model로 ResNet stem block (7 × 7 convolution + batch normalization + ReLU + max pooling)으로 Patch를 생성하여 ViT에 적용하였고 정확한 측정을 위해 기존 ViT모델의 head의 hidden layer을 제거하였습니다.
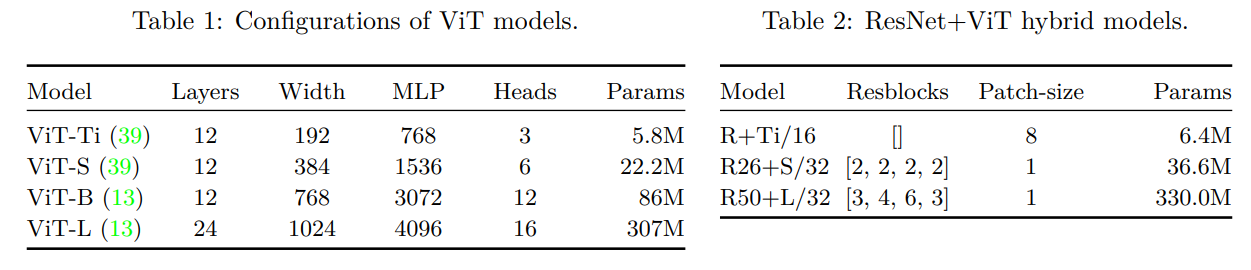
Patch 크기는 기본적으로 16으로 적용하면서 ViT-S와 ViT-B모델에는 32도 추가적으로 실험하였습니다. Data augmentation의 경우 Mixup과 RandAugment를 적용하였습니다.
4 Findings
4.1 Scaling datasets with AugReg and compute
본 논문에서의 가장 큰 발견은 Augmentations, Model Regularization과 data 크기에 따른 성능을 비교한 내용으로 일반적으로 모델과 데이터의 크기가 크면서도 AugReg를 적용하고 Epoch를 늘리면 좋은 성능을 나타내는 것을 알 수 있습니다. (AugReg + JFT-300M + training longer is best!)
4.2 Transfer is the better option
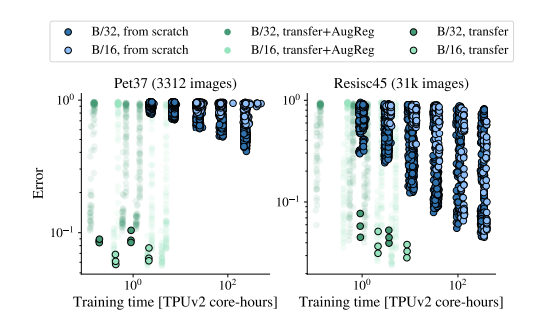
위 그래프에서와 같이 Scratch로 학습하는 경우 transfoer learning보다 좋은 성능을 보여주지 못하였고 Pre-training(ImageNet-21k)모델을 활용하여 transfer learning시에 AugReg를 적용했을 경우에 상대적으로 낮은 성능이 나오는 것을 확인하였습니다.
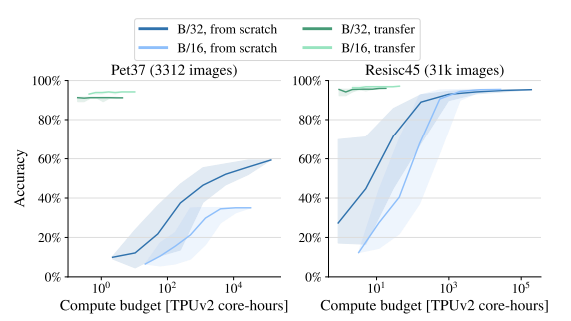
Patch크기가 큰 경우 학습이 빠르게 되면서 상대적으로 높은 정확도를 달성하였고 transfer learning의 경우에는 적은 학습량만으로도 scratch보다 높은 정확도를 달성하였습니다.
4.3 More data yields more generic models
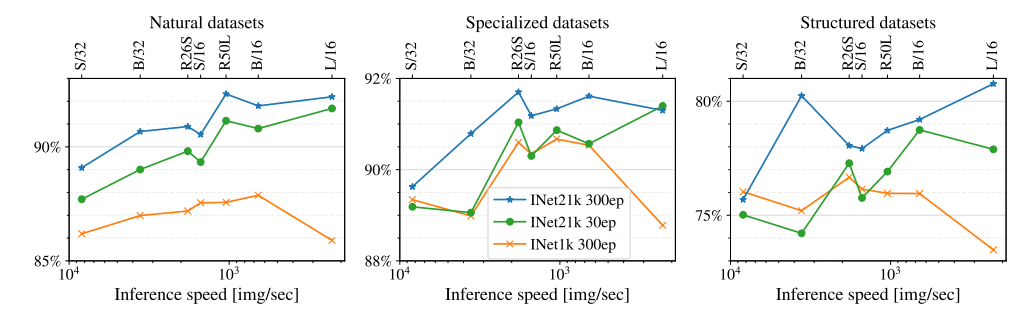
Pre-training의 성능을 검증한 결과로 VTAB의 도메인별(natural, specialized and structured) 별 데이터가 많을 수록 보다 높은 정확도를 보였고 적은 epoch로도 데이터량이 많으면 좋은 성능을 보이는 것을 볼 수 있고 큰 모델일 수록 inference속도가 느린 것을 확인할 수 있었습니다.
4.4 Prefer augmentation to regularization
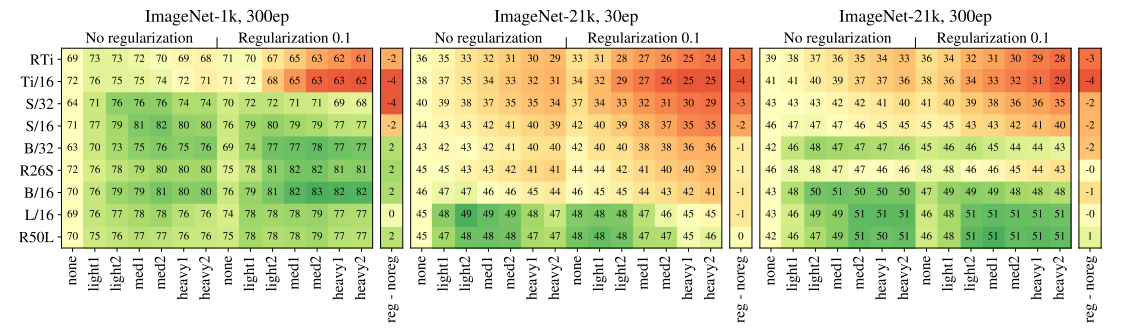
Augmentation과 regularization을 적용했을 때의 실험결과로 적은 data일 수록 AugReg 적용에 따른 효과가 높았고 Augmenataion만 적용했을때가 더 성능이 좋은 것을 볼 수 있습니다. 또한 epoch를 증가시킬 수록 성능이 나아지는 것을 확인하였습니다.
4.5 Choosing which pre-trained model to transfer
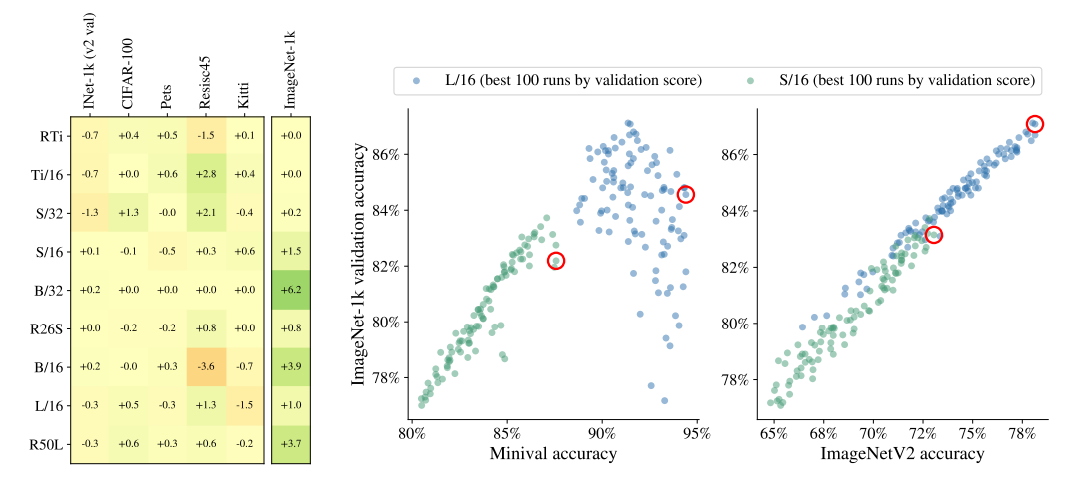
Upstream(ImageNet-21k)에서 Pre-training한 모델을 각각의 Downstream task에 적용할때 어떠한 모델을 적용하는 것이 좋은 성능을 보여주는 가에 대한 설명으로 왼쪽 그림에서와 같이 Reside45를 제외한 대부분의 모델이 Test data에서도 좋은 성능이 나오는 것을 확인할 수 있었고 ImageNet-1k의 경우 Pre-training의 데이터를 포함한 set으로 minival(1%의 Validataion set)로 평가한 모델의 경우 Overfitting된 것을 해결하기 위해 ImageNetV2를 test set으로 평가하면 correlation issue를 해결할 수 있었습니다.
4.6 Prefer increasing patch-size to shrinking model-size
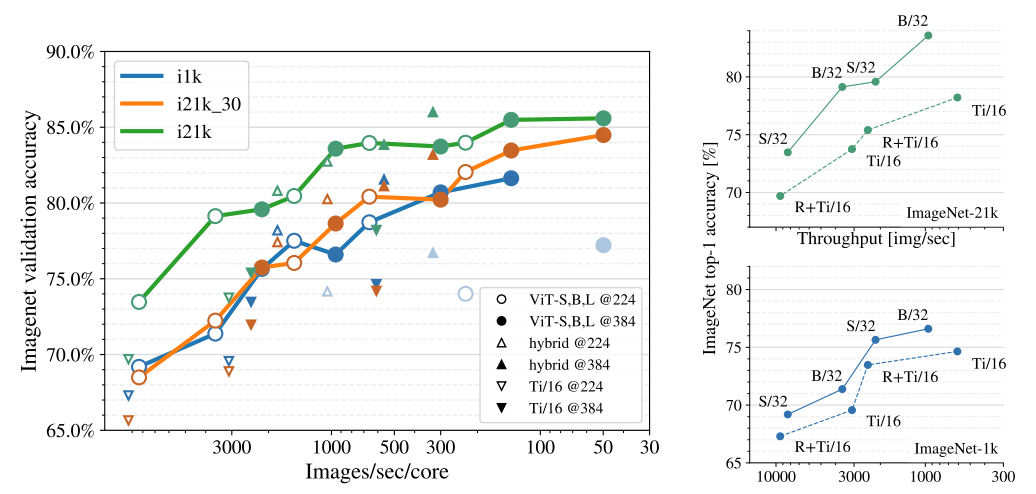
왼쪽 그래프의 경우 모델 크기와 Resolution이 클수록 성능이 좋아지는 것을 볼 수 있고 오른쪽 그래프의 경우 Patch의 크기가 클 수록 토큰의 수가 적어지는 반면 더 좋은 성능을 보여주는 것을 확인할 수 있었습니다. 따라서 모델 크기에 따라 파라미터의 수와 속도에는 영향을 주지 않는다고 볼 수 있습니다.
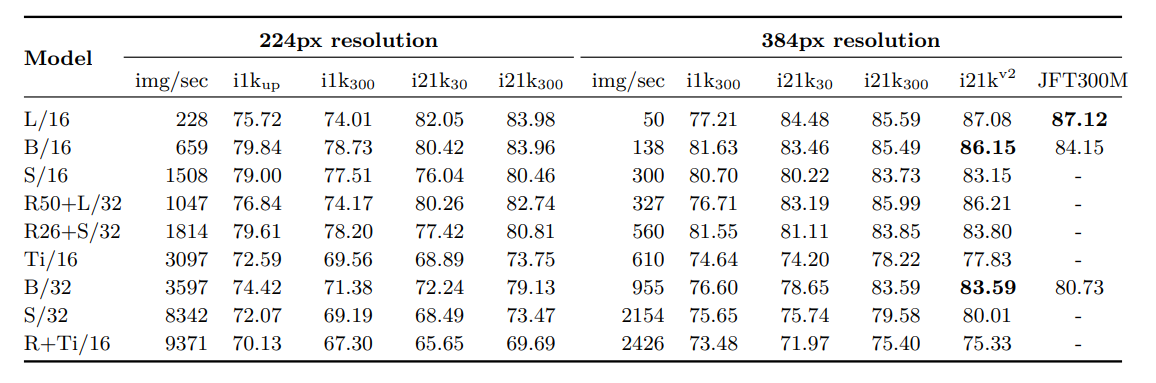
위 테이블에서도 Resolution이 큼에 따라 성능이 좋은 것을 볼 수 있고 소량의 데이터라도 AugReg적용을 통해 JFT300M보다 더 좋은 성능을 보여줌을 확인할 수 있습니다.(Bold 지표)
5 Related work
본 논문의 범위는 Vision Transformer의 pre-training과 transfer learning을 실험하면서 regularization과 augmentation의 효과를 검증하는데 초점이 맞춰있습니다.
ViT 논문이 나올 당시에는 Vision Transofrmer 아키텍쳐를 제시하면서 ImageNet-21k과 JFT-300M datasets을 활용하여 SOTA를 달성하였고 세부적인 regularization과 augmentation에 영향에 대해서는 분석은 되지 않았습니다. 또한 Big Transfer (BiT)[2]에서도 CNN을 활용하여 Pre-trainig의 성능에 대한 분석을 해 왔습니다. 최근에는 “Masked Autoencoders Are Scalable Vision Learners”에서 self-supervised learning의 적용에 따른 놀라운 성능을 보여주고 있습니다.
6 Discussion
본 논문에서는 다양한 실험을 위해 상당히 많은 GPU 자원을 필요로하고 반복적인 실험을 통한 시행착오와 이에 대한 결과를 공유함으로써 다른 연구자들이 초기 실험을 시작하는 상황에서 좋은 출발점이 될 수 있는 점이 크게 기여한 점이라 할 수 있습니다. 하지만 ResNets을 포함한 ViT 기본적인 아키텍쳐만을 활용하여 실험하였기에 Swin Transformer[3]과 같이 최근에 나온 다양한 ViT 아키텍쳐에 대한 실험이 필요합니다. (하지만 ViT기반 아키텍쳐들도 유사한 성능을 보여줄 것으로 생각합니다.)
7 Conclusion
본 논문에서는 컴퓨팅 자원이 제한된 상황에서 Vision Transformers 아키텍쳐 기반으로 pre-training을 효율적으로 학습하기 위해 regularization, data augmentation, model size, and training data size의 개별 성능을 상세히 분석하였고 세부적인 training parameter도 상세히 기술하였습니다. 향후 Vision Transformers 아키텍쳐를 활용한 실험에서 제한된 GPU에서의 성능을 검증하는데 유용하게 활용될 수 있을 것입니다.
[1] A. Dosovitskiy et al., “An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale,” ICLR, 2020.
[2] A. Kolesnikov et al., “Big Transfer (BiT): General Visual Representation Learning,” ECCV, 2020.
[3] Liu, Ze et al. “Swin Transformer: Hierarchical Vision Transformer using Shifted Windows.” arXiv, 2021.
Reviewed by Susang Kim
-끝-