import numpy as np
from sklearn.datasets import load_digits
from sklearn.neural_network import MLPClassifier
def load_data(X, Y):
# 학습 데이터는 앞의 800개를 사용하고, 테스트 데이터는 나머지를 사용
# X, Y 데이터의 타입은 Numpy array
X_train = X[:800]
Y_train = Y[:800]
X_test = X[800:]
Y_test = Y[800:]
return X_train, Y_train, X_test, Y_test
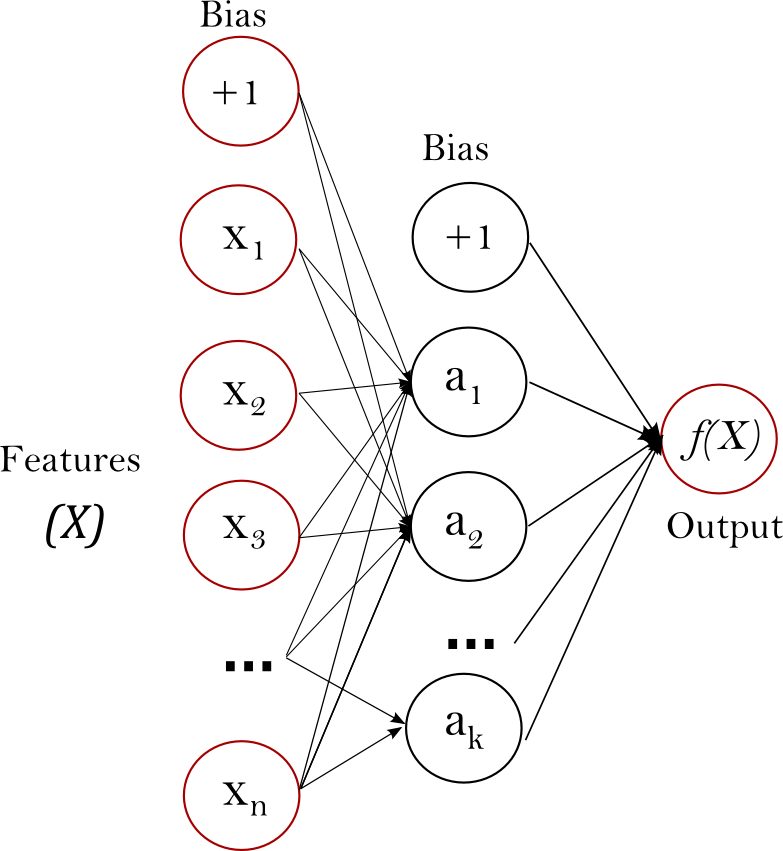
def train_MLP_classifier(X, Y):
# hidden_layer_sizestuple, length = n_layers - 2, default=(100,)
# The ith element represents the number of neurons in the ith hidden layer.
clf = MLPClassifier(hidden_layer_sizes=(150,200,150))
clf.fit(X, Y)
return clf
def report_clf_stats(clf, X, Y):
hit = 0
miss = 0
for x, y in zip(X, Y):
if clf.predict([x])[0] == y:
hit += 1
else:
miss += 1
score = hit/(hit+miss)*100
print("Accuracy: %.1lf%% (%d hit / %d miss)" % (score, hit, miss))
def main():
digits = load_digits()
X = digits.data
Y = digits.target
X_train, Y_train, X_test, Y_test = load_data(X,Y)
clf = train_MLP_classifier(X_train, Y_train)
score = report_clf_stats(clf, X_test, Y_test)
return score
if __name__ == "__main__":
main()